AMD FX-8150
"Bulldozer" CPU Review -
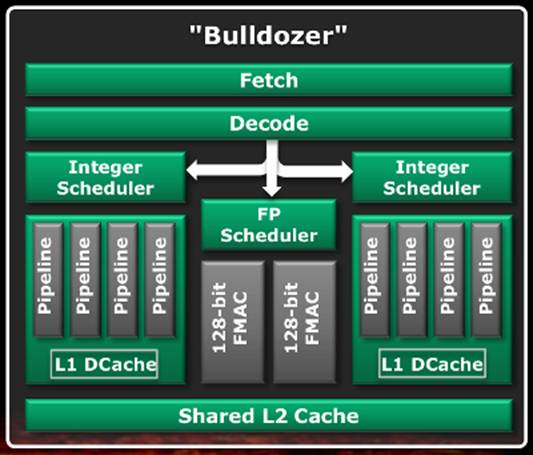
As
mentioned earlier, Bulldozer is a brand new architecture from AMD. It shares
nothing with the Phenom II. So how was it designed? Starting from the beginning,
reinventing the 4004 isn't quite how the engineers proceeded; decades of CPU
design cannot be thrown away so easily after all. Instead, AMD started off with
the general idea of what a modern processor looks like. Simply put, a processor
core is composed of instruction fetch and decode stages, the floating-point and
integer execution units, some cache, and a link to a northbridge which handles
memory access and further I/O. Single-core processors have now become quite
rare these days, with the exception of low-power platforms such as the
entry-level AMD Fusion processors, the Intel Atom or the VIA Nano, so at least
two cores are found in a chip.

This basic
concept has been improved over time, but it may have attained its limitations.
It needs some drastic changes to continue marching forward. AMD's focus here
was to maximize the instructions per watt while offering more cores, which is
the best way to increase the overall throughput of a server or cluster. The
smaller a core is, the more can be put in a chip, obviously. In this field of
engineering, there's a principle which says that the most common use case must
be favored. This does not go hand in hand with the fact that floating-point
operations account for only 20% of the CPU usage compared to 80% for integers
according to AMD, and that their operations are much more complex, thus
requiring lots of die space. In order to save some of it, AMD started off with
the idea of sharing one FPU over two cores. However, many computing
applications make intensive use of them, and newer sets of instructions have
recently appeared to boost their performance, such as the 256-bit Advanced
Vector eXtensions (AVX) featured on Intel Sandy Bridge processors. The FPU in
Bulldozer does support them as well, but when they are not in use, each core in
the module has access to half of the pipelines for 128-bit calculations.
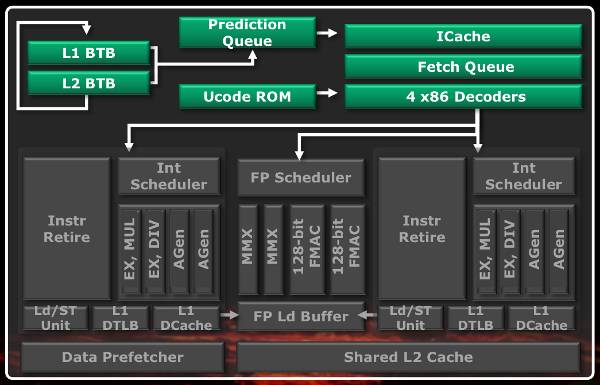
The saved
die space has been spent on aggressive features that benefit both cores, namely
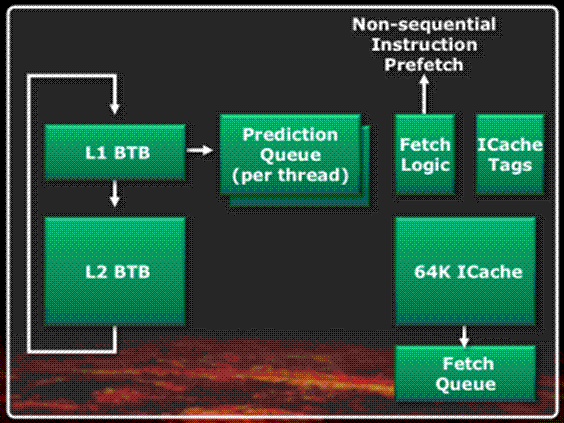
prefetching. The shared frontend prefetches instructions in a dynamic fashion,
according to the destination addresses of branches stored in the two levels of
the branch target buffer that are 512B and 5KB in size, respectively. For those
unfamiliar with the branch prediction concept, what's basically stored in these
buffers is the actual memory address of the instruction located at the branch
destination. There is a rule of thumb which states that a processor spends 90%
of its time in 10% of the code; when a branch is being taken, it is likely to
be taken again very soon, so keeping its previous target at hand instead of
waiting for its computation can save some precious cycles. The prediction
pipeline is free to run as long as its queue (dedicated for each thread) is not
full. By looking at the Relative Instructions Pointers (RIP), the instruction
fetch pipeline can then predict future cache misses. As for the 64KB
instruction cache, the two threads compete dynamically for it. There is a
slight problem though; in some specific cases, there can be an excessive number
of cache invalidations, forcing the instructions to be fetched again. There was
a discussion back in July
 between some folks at AMD and some other guys, namely
Mr. Linus Torvalds himself, about patching the Linux kernel to prevent
this, which currently hasn't been done. Supposedly this would lead to a 3%
sacrifice in performance, but rumors posit this to be higher on Windows. This
bug doesn't affect the viability of the system like the Intel P67's premature
SATA degradation or the AMD TLB bug did, though. Fixing it in the next core
revision would of course be better than software workarounds, and allow for a
measurable performance boost. Finally, another big difference with Phenom II is
the addition of a fourth instruction decoder, which puts it on par with Sandy
Bridge. All of these improvements should help maximize the use of the execution
units.
between some folks at AMD and some other guys, namely
Mr. Linus Torvalds himself, about patching the Linux kernel to prevent
this, which currently hasn't been done. Supposedly this would lead to a 3%
sacrifice in performance, but rumors posit this to be higher on Windows. This
bug doesn't affect the viability of the system like the Intel P67's premature
SATA degradation or the AMD TLB bug did, though. Fixing it in the next core
revision would of course be better than software workarounds, and allow for a
measurable performance boost. Finally, another big difference with Phenom II is
the addition of a fourth instruction decoder, which puts it on par with Sandy
Bridge. All of these improvements should help maximize the use of the execution
units.
Each ALU
has its own thread scheduler. One can see the pipelines for division and
multiplication, as well as address generation. The latter serves the fully
out-of-order load and store unit, which can handle two 128-bit loads and one
128-bit store per cycle. The queue for each of these operation is 40
and and 24-entry long, respectively, and the data cache is 16KB in size.
There's also some register renaming going on in there to avoid unnecessary data
hazards, or dependencies. For example, if one instruction stores the value of a
given register in memory, and the following instruction wants to use the same
register for storing the result from the ALU, the result will be put in another
register instead of waiting for the memory store to be completed.
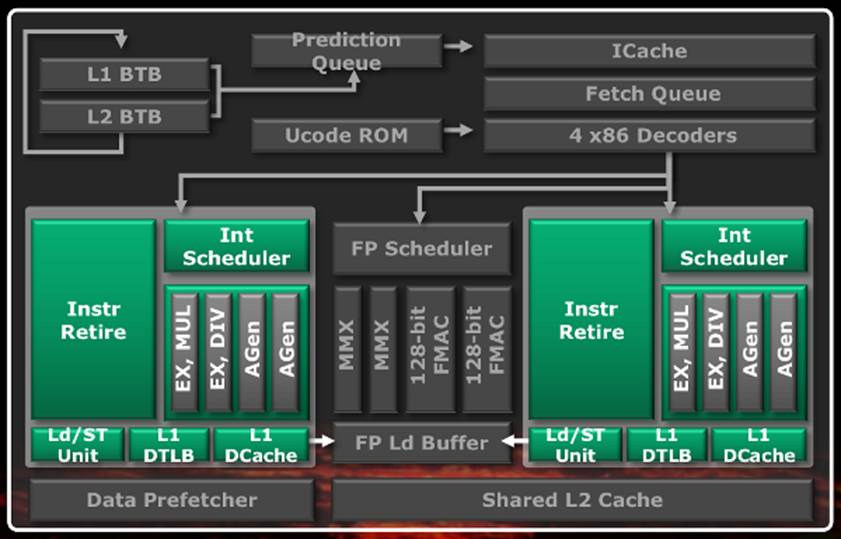
The FPU, as
explained above, is shared between two cores. To allow such a configuration,
AMD has adopted a coprocessor arrangement. The unified FP scheduler manages
both threads, and when the execution is completed, the parent core is advised.
Two of the pipelines consist of Fused Multiply-Accumulate (FMAC) which, in the
four operand form adopted by AMD, can be described as follows with the arrow
representing a store operation: A ← B + C x D. The upcoming processors
from Intel are also going to feature FMA pipes, however they are going to be in
the three operand, or destructive form, like this: A ← A + B x C.
Obviously, keeping A unmodified has its advantages. If it needs to be used for
other operations, it will need to be copied over to other registers before
doing an FMA3 operation, thus adding more instructions. To maintain
compatibility, AMD will also support the three operand form in the next core,
dubbed Piledriver. The other two pipelines
in the coprocessor are actually integer pipelines, which can also work with
128-bit operands for the SSE instructions. They take care of the operations in
the XOP instruction set as well, which along with FMA4, forms what was
originally supposed to be SSE5, first proposed by AMD back in 2007. Once again
the reason for this change is to have a better compatibility with Intel's
instruction set. XOP contains integer vector operations such as
multiply-accumulate, compare, shift, rotate, permute, and more. So there is a
great opportunity for developers to get tremendous boosts in speed with these
new SIMD instructions.

Then there
is the 16-way unified L2 cache, 2MB in size. Since it is shared between two
cores on eight, the core on which a given thread is scheduled might affect
peformance; if two threads of a program are in the same module, they will share
their L2, otherwise they have to rely on the slower L3. The Windows scheduler
is obviously not aware of such a detail of the implementation, but supposedly
the Windows 8 developer preview shows some benefits due to its better
scheduler. What is important to note also is that unlike the L1 cache, the L2
is exclusive in regard to its higher sibling which results in a total of 16MB
of data. Additionally, the 8-way L2 translation lookaside buffer, used to do
the conversion between virtual and physical memory addresses, has 1024 entries
and services both the instruction and data requests. Finally, there are data
prefetchers which try to predict data use and bring it into cache ahead of when
the processor executes the load.
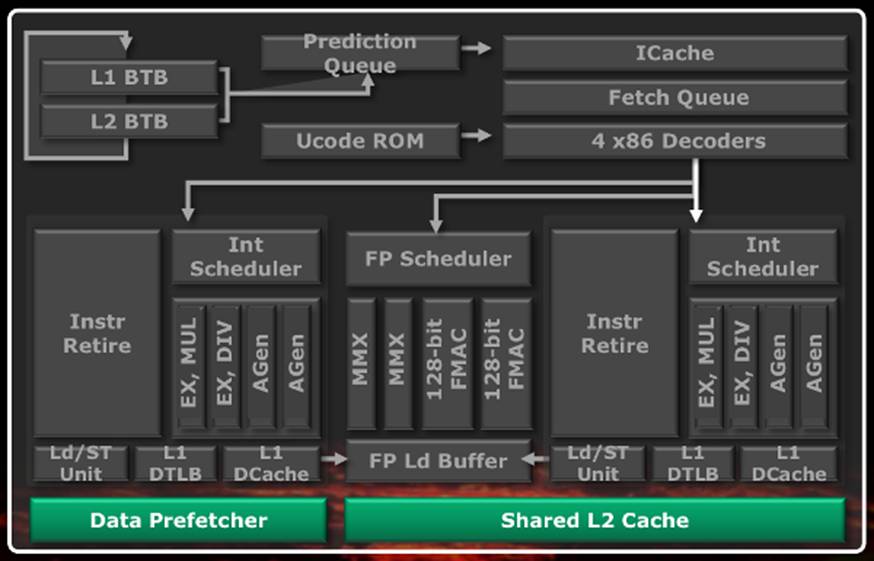
The
integrated northbridge has also been redesigned. After the synchronization
between the four modules, the requests are sent to either the L3 cache or the
memory and the rest of the system via the HT link. There are also two
Advanced Programmable Interrupt Controllers (APIC).

There is
also an Application Power Management (APM) module somewhere in there which
measures the TDP headroom for the Turbo Core 2.0. If there is enough of it, all
cores can get a 300MHz increase, significantly boosting the performance.
This case happens when an application uses more than four cores, but
doesn't load them up to 100%. The major difference with the previous version
seen in the Thuban die is the addition of a second Turbo mode. If no more than
half of the cores are active, the unused modules can go into C6 state and allow
the others to level up another 300MHz, for a total of 600MHz on the FX-8150. On
the FX-8120 model, this ramps up to 900MHz higher than stock! Again, there is a
small hiccup with the current Windows scheduler; if the threads are not running
on the right modules, this Turbo mode won't work. Hopefully a patch to the
Windows 7 scheduler will soon arrive.

That C6
state implies power gating the whole unused module. First, after a
predetermined period of inactivity, the L2 cache is flushed and the register's
content is saved. Then, some FETs essentially isolate
the module from the ground. To resume, they close back the loop and the
execution context is restored from the saved space. There is also some clock
gating going on in the modules, which is essentially bringing the frequency
down to zero, but at a more granular level. Some parts of the northbridge can
also be power gated if not used.

CROSSHAIR V FORMULA-Z
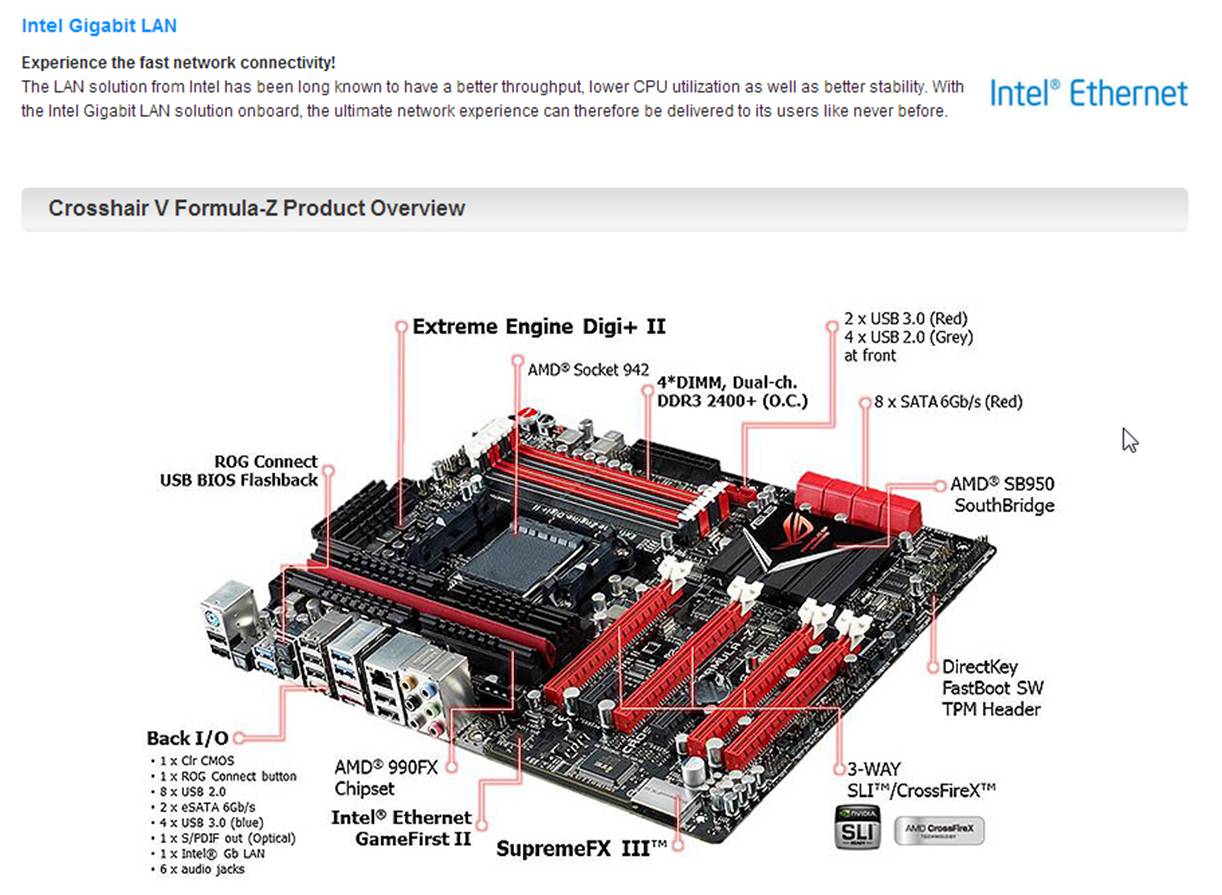
Upgraded 990FX motherboard with
exclusive ROG gaming audio and networking technologies
·
Extreme Engine Digi+ II -- Powerful combination of analog and digital
design elements
·
SupremeFX III -- Play with ultra-real cinematic in-game surround sound!
· GameFirst
II-- Put your frags first
·
3-Way NIVDIA® SLI™ / AMD CrossFireX™ Technology
·
Intel® Gigabit LAN -- Experience the fast network connectivity!
·
UEFI BIOS -- Flexible & Easy BIOS Interface
·
Supercharged Audio and Ultrafast LAN
· Windows 8 Ready – Assured
Compatibility




![]()
Add To Compare ListPrint

·
Overview
·
Award
·
Download
 The
The
CPU Features
FX™/Phenom™ II/Athlon™ II/ Sempron™ 100
Series Processors (AM3+ CPU)

 This motherboard supports latest AMD® Socket AM3+ multi-core processors
with up to 8 native CPU cores and delivers better overclocking capabilities with
less power consumption. It features AMD® Turbo CORE Technology 2.0 and
accelerates data transfer rate up to 5200MT/s via HyperTransport™ 3.0 based
system bus. This motherboard also supports AMD® CPUs in the new 32nm
manufacturing process.
This motherboard supports latest AMD® Socket AM3+ multi-core processors
with up to 8 native CPU cores and delivers better overclocking capabilities with
less power consumption. It features AMD® Turbo CORE Technology 2.0 and
accelerates data transfer rate up to 5200MT/s via HyperTransport™ 3.0 based
system bus. This motherboard also supports AMD® CPUs in the new 32nm
manufacturing process.
Chipset Feature
AMD 990FX Chipset
 AMD® 990FX Chipset is designed to
support up to 5.2GT/s HyperTransport™ 3.0 (HT 3.0) interface speed and dual PCI
Express™ 2.0 x16 graphics. It is optimized with AMD® latest AM3+ and multi-core
CPUs to provide excellent system performance and overclocking capabilities.
AMD® 990FX Chipset is designed to
support up to 5.2GT/s HyperTransport™ 3.0 (HT 3.0) interface speed and dual PCI
Express™ 2.0 x16 graphics. It is optimized with AMD® latest AM3+ and multi-core
CPUs to provide excellent system performance and overclocking capabilities.
Multi-GPU Technology
SLI™/CrossFireX™ On-Demand
![]()
 Why choose when you can have both?
Why choose when you can have both?
SLI™ or CrossFireX™? Fret no longer because with the Crosshair V Formula-Z
you’ll be able to run both multi-GPU setups. The board features SLI™/CrossFire™
on Demand technology, supporting up to four graphics cards in a Quad-GPU SLI or
3-Way SLI™ / CrossFireX™ configuration. Whichever path you take, you can be
assured of jaw-dropping graphics at a level previously unseen.
Memory Feature
DDR3 2400(O.C.) Support
This motherboard supports DDR3
2400(O.C.) that provides faster data transfer rate and more bandwith to
increase memory computing efficiency, enhancing system performance in 3D
graphics and other memory demanding applications.
Sound with Clarity
SupremeFX III
 Supreme Sound
Supreme Sound
The SupremeFX III™ onboard audio solution is an 8-channel HD audio equipped
with a carefully selected 1500uF capacitor which provides clean, ripple-free
audio power and – perfect for enveloping gaming environments. With a metallic
EMI cover and special layout design on the PCB, advanced SupremeFX Shielding™
technology isolates analog audio signals from digital sources for exceptional
clarity and high fidelity, while a gold-plated jack ensures rich notes reach
your ears with minimal distortion.
ROG
Exclusive Features
Extreme Engine Digi+ II
 Powerful combination of analog and digital design elements
Powerful combination of analog and digital design elements
The Extreme Engine Digi+ II has been upgraded, while
the digital VRM design allows you to achieve ultimate performance with
adjustable CPU and memory power management frequencies. Precise adjustments
create greater efficiency, stability, and performance for total system control.
ROG Connect
 Plug and Overclock
- Tweak it the hardcore way!
Plug and Overclock
- Tweak it the hardcore way!
Monitor the status of your desktop PC and tweak its parameters in real-time via
a notebook—just like a race car engineer—with ROG Connect. ROG Connect links
your main system to a notebook through a USB cable, allowing you to view
real-time POST code and hardware status readouts on your notebook, as well as make
on-the-fly parameter adjustments at a purely hardware level.
GameFirst II
 The speed you need to pwn
The speed you need to pwn
Low Internet latency allows you to frag more, and get
fragged less. That's why ROG has introduced GameFirst, a feature that manages the flow of traffic
according to your needs so that you can still listen to online music, download
and upload files, and engage in Internet chats without sacrificing the low ping
times you need to pwn your opponents.
CPU Level Up
 A simple click for instant upgrade!
A simple click for instant upgrade!
Ever wish that you could have a more expansive CPU? Upgrade your CPU at no
additional cost with ROG's CPU Level Up! Simply pick
the processor you wanted to OC to, and the motherboard will do the rest! See
the new CPU speed and enjoy that performance instantly. Overclocking is never as easy as this.
GPU.DIMM Post
 Easily check the status of your graphics
cards and memory in the BIOS!
Easily check the status of your graphics
cards and memory in the BIOS!
Notice potential problems even before you enter the OS! Overclockers
can save valuable minutes in detecting component failure under extreme
conditions. With GPU.DIMM Post, quickly and easily check your graphics cards
and memory DIMMs status in the BIOS, potentially keeping
that record-breaking overclock!
BIOS Print
 One click, easily share your BIOS
settings
One click, easily share your BIOS
settings
ROG offers a whole new EFI BIOS feature to handle the demands of an overclocking experience. Crosshair V Formula-Z features ROG
BIOS Print which allows users to easily share their BIOS settings to others
with the press of a button. The days of using a camera to take BIOS screenshot
are over.
ROG Bundled
ROG CPU-Z
 Whole new design of CPU-Z
Whole new design of CPU-Z
ROG CPU-Z is a customized ROG version authorized by CPUID. It has the same
functionality and credibility as the original version, with a unique design.
Use the whole new look of ROG CPU-Z to truly report your CPU related
information and your uniqueness.
Kaspersky® Anti-Virus
 The best protection from viruses
and spyware
The best protection from viruses
and spyware
Kaspersky® Anti-Virus Personal offers premium
antivirus protection for individual users and home offices. It is based on
advanced antivirus technologies. The product incorporates the Kaspersky® Anti-Virus engine, which is renowned for
malicious program detection rates that are among the industry's highest.
DAEMON Tools Pro Standard
 The real tool for optical and
virtual discs
The real tool for optical and
virtual discs
DAEMON Tools Pro offers essential functionality to backup CD, DVD and Blu-ray discs. It converts optical media into virtual discs
and emulates devices to work with the virtual copies. DAEMON Tools Pro
organizes data, music, video and photo collections on a PC, notebook or netbook.
Other Features
Intel Gigabit LAN
Experience the fast network
connectivity!
![]() The LAN solution from Intel has
been long known to have a better throughput, lower CPU utilization as well as
better stability. With the Intel Gigabit LAN solution onboard, the ultimate
network experience can therefore be delivered to its users like never before.
The LAN solution from Intel has
been long known to have a better throughput, lower CPU utilization as well as
better stability. With the Intel Gigabit LAN solution onboard, the ultimate
network experience can therefore be delivered to its users like never before.